
")
The theory behind SQL Query Execution time:
A database is a piece of software that runs on a pc/server, and is subject to the very same constraints as all software–it can only process as much information as its hardware is capable of handling. The best way to create a query run faster would be to reduce the number of calculations that the software (and therefore hardware) should perform. To do it, you’ll need some understanding of how SQL really makes calculations. First, let’s address a number of these high-level items that will impact the number of calculations you need to make, and therefore your queries runtime:
- Table dimension: If your query hits a couple of tables with millions of rows, hundreds of columns, or even more, it might influence functionality.
- Aggregations: Mixing multiple rows to produce a result requires more computation than simply regaining these rows.
- Joins: In case your query joins two tables in a way that considerably increases the row count of the result set, your query is very likely to be slow
Query runtime is Also dependent on some things which you can’t really control associated with the database :
Other users running queries: The more queries running concurrently on a database, the more the database should process at a given time and the slower everything will operate. It can be awful if others are operating especially resource-intensive queries that meet a number of the above criteria.
Database optimization and software: This is something that you probably can not control, but if you understand the system you’re using, you can work within its bounds to make your queries more efficient.
For now, let’s Dismiss the things you can’t control and operate on the things we can fix and improve MySQL Query performance
Scan targeted rows & Avoiding Full Table Scans
Filtering the results of a SELECT statement with a WHERE clause suggests retrieving only a subset of rows from a larger set of rows. The WHERE clause can be used to either include desired rows, exclude unwanted rows or both.
Filtering the data To include only the observations you need can dramatically improve query speed. How you do that will depend entirely on the problem you are trying to solve. For example, if you’ve got time-series data, limiting to a small-time window can make your queries run much more quickly with optimal index/es.
There are many factions depending on to select optimal index. In case if there is no good index then it go full scan or it will scan to many unwanted rows. In case you are not DB performance expert then better to tune your SQL queries with DB performance expert. Also, SmartWorkbnech is one of the best tools for recommending the Optimal index.
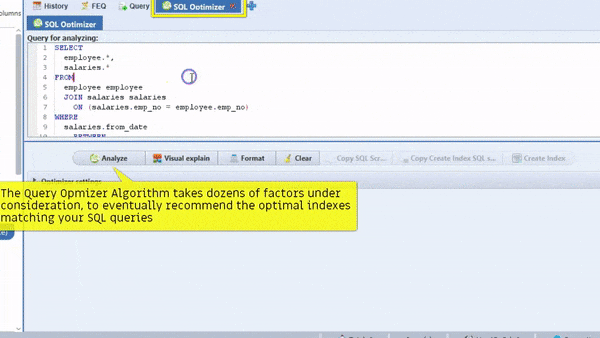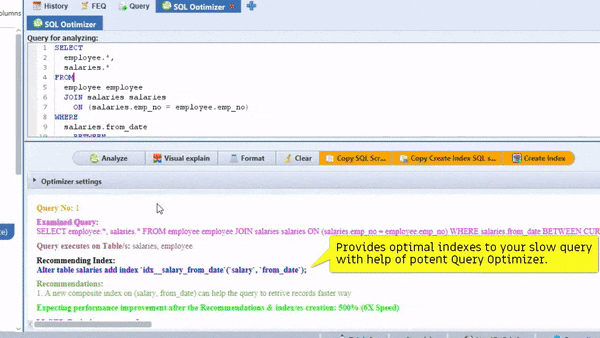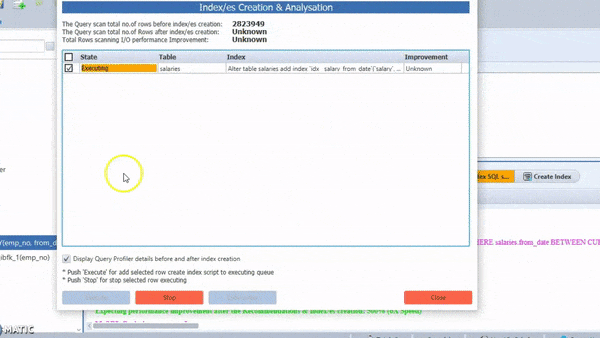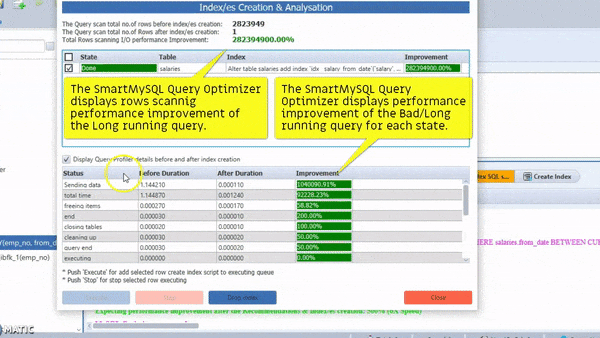
Remember that You could always perform exploratory analysis on a subset of data, refine your Work into a final query, then remove the limitation, and run your job across The whole dataset. The final query might take a long time to run, but at least It’s possible to run the intermediate steps quickly.
Where clause Operators Efficiency
Any Equals (=) and range operators <, >, <=, >=) and the BETWEEN operator. In general, the = operator will execute an exact row hit on an index and thus use unique index hits. The range operators will usually require the optimizer to execute index range scans. the most commonly used indexes in MySQL Database, are highly amenable to range scans
So try to always do two things with WHERE clauses.
- Firstly, try to match comparison condition column sequences with existing index column sequences, although it is not strictly necessary.
- Secondly, always try to use unique, single-column indexes wherever possible. A single-column unique index is much more likely to produce exact hits. An exact hit is the fastest access method.
Making Table Joins less complicated
A join is a combo of rows extracted from a few tables. Joins can be quite specific, for instance, an intersection between two tables, or they can be specific like an outer join. An outer join is a join returning an intersection and rows from both tables, maybe not at the other table.
Incorrect Idea of Primary Key selection in JOIN condition:
This case happens when you assume that a certain column is a primary key but it is not in fact unique.
Result
As a result of a link with this type of column, you receive values for an element which exists in the principal table over once doubled (or tripled, etc.). This creates a critical error to your results and it’s not always obvious to see.
Solution
- Test the uniqueness of this column.
- Check primary and unique keys
- Test uniqueness (see query below)
- Check documentation (if exists)
The query below tests the uniqueness of projects_no column in the table. If the query returns any row column is not unique.
Select project_no, count(*) From jobs group by project_no having count(*) > 1
Please note that if values are somewhat unique at the time of execution of this question that this doesn’t mean that it will always be . This may change with new data.
When you know the relation between the tables only add more condition to your join statement.
Take this instance, which joins advice about college sports teams onto a list of players in different colleges:
SELECT players.school_name, COUNT(1) AS gamers FROM college_football_players players JOIN college_football_teams teams ON teams.school_name = players.school_name GROUP BY 1,2
That means that 26,998 rows will need to be assessed for matches in a different table. But in case the college_football_players table was pre-aggregated, you can reduce the number of rows that need to be assessed in the join. First, let’s look at the aggregation:
SELECT players.school_name, COUNT(*) AS gamers FROM college_football_players players GROUP BY 1
So dropping that at a sub-query and connecting to it at the outside query will reduce the Expense of the link considerably:
SELECT teams.conference, sub. * FROM ( SELECT players.school_name, COUNT(*) AS players players GROUP BY 1 ) sub JOIN college_football_teams teams ON teams.school_name = sub.school_name
In this particular instance, You won’t see a huge gap because 30,000 rows isn’t too difficult for the database to process. But if you’re talking about thousands and thousands of Rows or longer, you’d notice a noticeable improvement by aggregating before joining. Whenever you do this, be certain that what you’re doing is logically consistent–you must worry about the truth of your work before worrying about run speed.
Inefficient Joins
What is an ineffective join? An inefficient link is an SQL query linking tables which is difficult to tune or cannot be tuned to a decent level of functionality. Certain types of join queries are inherently both poor performers and hard if not impossible to optimize SQL queries. Inefficient joins are best avoided.
Avoid Anti-Joins
An anti-join is always a problem. An anti-join simply does the opposite of a requirement. The result is that the Optimizer must search for everything not meeting a condition. An anti-join will generally always produce a full table scan as seen in the first example following. The second example uses one index because indexed columns are being retrieved from one of the tables. Again the Rows and Bytes columns are left as overflowing showing the possible folly of using anti-joins Example.
SELECT t.text, coa# FROM type t, coa WHERE t.type != coa.type;
Avoid Cross JOIN / Cartesian Products
A Cross Join is just tunable up to columns selected match indexes such that rows are retrieved from indexes and not tables. For example, the following query has a lower cost than the original because the selected columns match indicators on both tables. I have left the Rows and Bytes columns from the query plans as overflowed numbers replaced with a series of # characters. This is done in order to stress the pointlessness of employing a Cartesian product in a relational database.
SELECT * FROM coa, generalledger;
An equi-join uses the equals sign (=) and a range join uses range operators (<, >, <=, >=) and the BETWEEN operator. In general, the = operator will execute an exact row hit/scan on an index and thus use unique index hits. In DB, the range operators will usually require the optimizer to execute index range scans. Generally, the most commonly used indexes in MySQL Database, are highly amenable to range scans. A BTree index is little like a limited depth tree and is optimized for both unique hits and range scans.
So how can a join be tuned? There are a number of factors to consider.
- Use equality first.
- Use range operators only where equality does not apply.
- Avoid the use of negatives in the form of != or NOT.
- Avoid LIKE pattern matching.
- Try to retrieve specific rows and in small numbers.
- Filter from large tables first to reduce rows joined.
- Retrieve tables in order from the most highly filtered table ; rather
the largest table has the most filtering implemented. The most highly filtered table is the table with the lowest proportion of its rows recovered, rather the largest table. - Use indexes wherever possible except for very small tables.
- Let the Optimizer do its job.
Avoid Functions in the WHERE [ORDER BY/GROUP BY] Clause
When using works in SQL statements it is ideal to maintain away the functions from any columns between index matching. Moreover, it’s the best practice to avoid acts as shown in the below example.
In case, If you can’t avoid function then try to create function columnsn(> MySQL 8.0 support). alternatively, use generated columns
Avoid the operations & expressions with index columns
B+ tree indexes are sensitive, if you convert index column values in the query then indexes are not useful for your query. Avoid operations and expression with an index column as shown in the below example.
Avoid OR Logical operators and convert it to UNION query
B+ Tree index could not work efficiently with Query’s WHERE filter conditions with OR logical operator. However, It is highly recommended to convert the OR operation to UNION queries. Example.
Column Prefix Key Parts
Normally, Indexes need the same or longer amount of data saved distance. In MySQL, Prefix indicators can be considerably smaller in size and with no indicator being covering index, which means query can be executed using only data in the index without studying the row .
Prefixes can be specified for CHAR, VARCHAR, BINARY, and VARBINARY key parts and should be specified for BLOB and TEXT key parts. The next is an example how efficiently we can create an index
MySQL Query Optimization of the ORDER BY clause
In general, it is difficult for the performance tuning elements of the ORDER BY clause. This is only because re-sorting is executed after everything else has completed. The ORDER BY clause should not be allowed to conflict with the best Optimizer performance choices of former clauses. An ORDER BY clause may be used as a refinement of previous clauses instead of replacing those previous clauses. The WHERE clause will filter rows and the ORDER BY re-sorts those filtered rows. The ORDER BY clause can sometimes convince the Optimizer to use a less effective key.
So that the ORDER BY clause is always executed after the WHERE clause. This doesn’t mean that the Optimizer will select either the WHERE clause or the ORDER BY clause as the best performing factor. Try not to reevaluate the WHERE clause with the ORDER BY clause because the Optimizer might decide on a less effective process of execution depending on the ORDER BY clause.
the SmartMySQL is one of the best tools for Optimize SQL queries with optimal index and it can rewrite effective SQL to improve query performance more than 100X
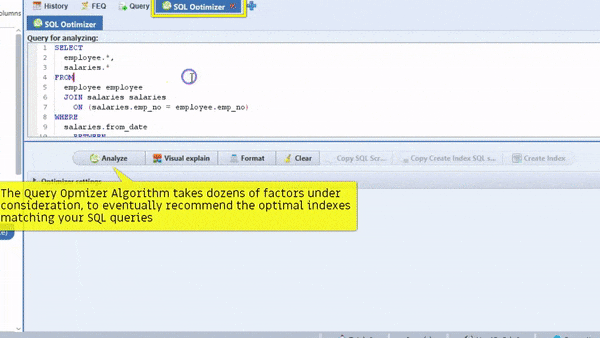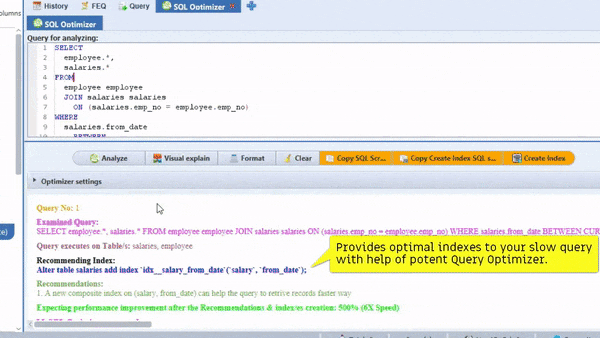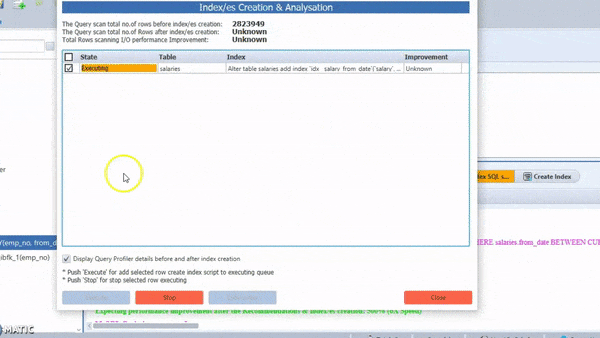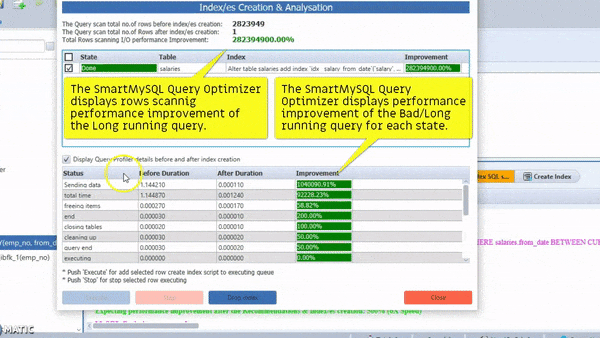
Most importantly, it can show performance improvement stats


















{kind=link}